 官方微博
官方微博一流科技正式上线OneFlow v0.5版:四大特性实现轻快上手,高效、易用从此兼得
9月27日,在中关村论坛国际技术交易大会上,一流科技创始人&CEO袁进辉宣布深度学习框架OneFlow v0.5.0正式上线GitHub,他重点介绍了OneFlow v0.5.0的四大特性。本次产品升级也是OneFlow自2020年7月31日开源以来,功能发布最重磅的版本。

高效、易用、完备是任一深度学习框架在未来竞争中胜出的必由之路。在用三年时间对最难的分布式计算和高效性问题进行攻关后,OneFlow开源以来,已历经五次版本更迭,重点从优化编译、API接口等层面攻关易用性体验,同时持续优化分布式性能,保持业界领先地位。
一方面,OneFlow框架一开始就瞄准最具挑战的高效性,攻占技术制高点,并以此成为立足业界的安身之本。另一方面,随着OneFlow v0.5.0的发布,OneFlow将带给开发者革命性的易用性体验,同时,也从全局视角打破了深度学习框架易用性和高效性不可兼得的桎梏,向着全球范围内最好用深度学习框架的目标迈出了坚实的一大步。
本次产品升级也入选了2021年度中关村论坛“百项新技术新产品榜单”。

四个“一”实现极致易用性体验
相比此前的版本,OneFlow v0.5.0在易用性上实现了四大技术特性。
一行代码实现OneFlow与PyTorch切换
凭借易用性,PyTorch在深度学习框架市场异军突起,其在单卡的eager mode,pythonic,面向对象编程等使用设计上广受认可。新发布的OneFlow v0.5.0也接收了其设计想法,使其在编程API层面和PyTorch严格对齐,并对齐了相关模型的200多个算子。
对喜欢使用PyTorch的eager模式的开发者来说,只需更改一行代码,就可以让PyTorch上写的代码在OneFlow中跑起来。
一段代码实现动态图与静态图转换
在编码调试阶段,动态图的编程模式的体验最好,但当模型稳定后,静态图模式在运行效率方面更有优势。因此,最理想的框架是同时支持二者,使用户在一个框架上享受到最佳的动、静态体验,并且最好动、静态图可以自由转换。
在OneFlow v0.5.0中,开发者只需把使用动态模式开发的代码用nn.Graph封装起来,就可以享受静态图的好处。当然,要想实现完全自动的动、静态转换,还需要进一步攻关。
一致性视角实现单机和分布式无缝切换
随着数据和模型的规模越来越大,单卡和单机已经不能满足开发者的需求,很多工业级的深度学习模型必须在分布式集群上训练。
然而,由于分布式编程的门槛太高,且大部分算法科学家对分布式编程并不熟悉,这给分布式训练带来一定挑战。
为了让开发者无须关注复杂的分布式底层细节,只专注于逻辑层面的神经网络搭建,OneFlow创造性地发明了一致性视角(Consistent View)的概念,把分布式的多卡模拟成一块超大的虚拟设备,统一了单机和分布式的编程接口,从而方便让算法工程师低成本使用分布式计算来加速。
一套系统支持各种并行模式
不同神经网络的最优并行方法并不相同,像CNN这类大数据、小模型的神经网络层次最好用数据并行,对超大的全连接层这种模型更大的层次最好用模型并行,对于feature map超大或者层次超深的神经网络更适合流水并行。
但很不幸,原有主流框架仅支持常用的数据并行,要想使用模型并行或者流水并行功能,就必须借助某种插件或者做深度定制,而且这种定制系统都只能用于HugeCTR,Megatron-LM等某一种类型的神经网络。
OneFlow在系统层面支持了数据并行、模型并行和流水并行,不需要额外的插件和定制开发,就可以以最小代码量高效支持任何神经网络。
“人有我优,人无我有”的高效性
要知道,原有深度学习框架都聚焦于单卡的用户体验,仅对适合数据并行的多机多卡场景处理的较好,但遇到Wide and Deep模型 、 GPT-3等超大模型,开发者就会面临多机多卡编程难、效率低下或无法实现等分布式深度学习的痛点。
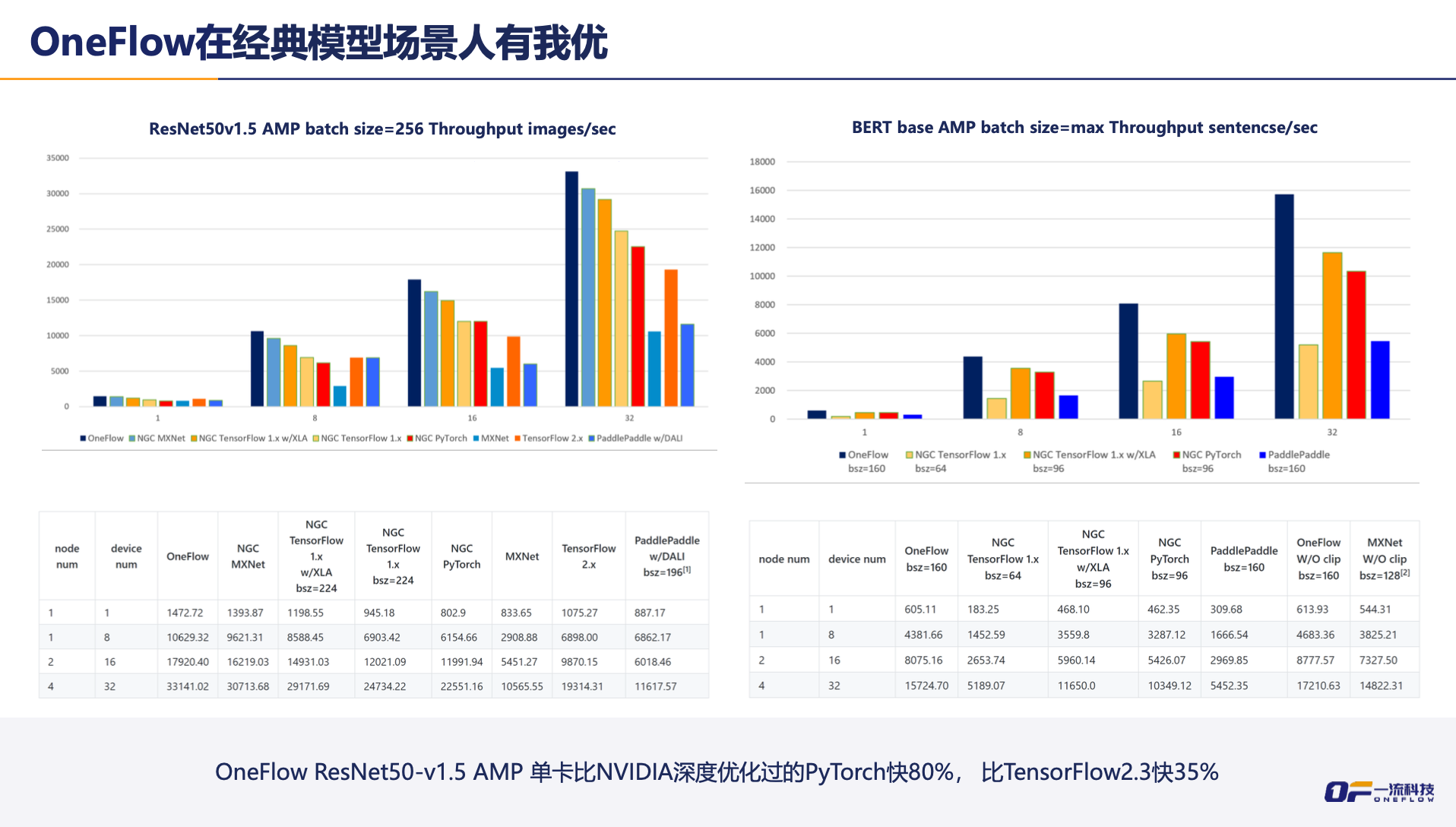
尽管这些框架通过改进框架设计或研发NCCL 、 Horovod 、 HugeCTR等第三方插件的方式取得了一些进步,但受限于框架本身架构设计的不足,仍不能满足用户对极致性能的需求 ,而OneFlow在这方面的优势可以概括为“人有我优”和“人无我有”,是所有框架中的最优解决方案。

支撑 OneFlow 高效性的背后有四大关键技术,其中静态调度和流式执行均为业界首创:
编译器自动编排并行模式和流水线:编译器自动解决从逻辑任务到硬件资源的映射,包括数据并行、模型并行、流水并行的设备分配以及数据路由方案,大大降低分布式编程的复杂度,用户只须关心任务的逻辑结构以及本次任务可使用的硬件资源,而不用去编程实现数据在硬件资源中的流动机制。
静态调度:把所有能在正式运行之前得到的调度策略、资源管理策略等问题都在编译阶段解决,运行时不需要在线求解最优的调度方案,从而大大降低运行时开销。为了让用户在使用高度动态模型时也有良好的体验,OneFlow内部有动静两套执行机制。
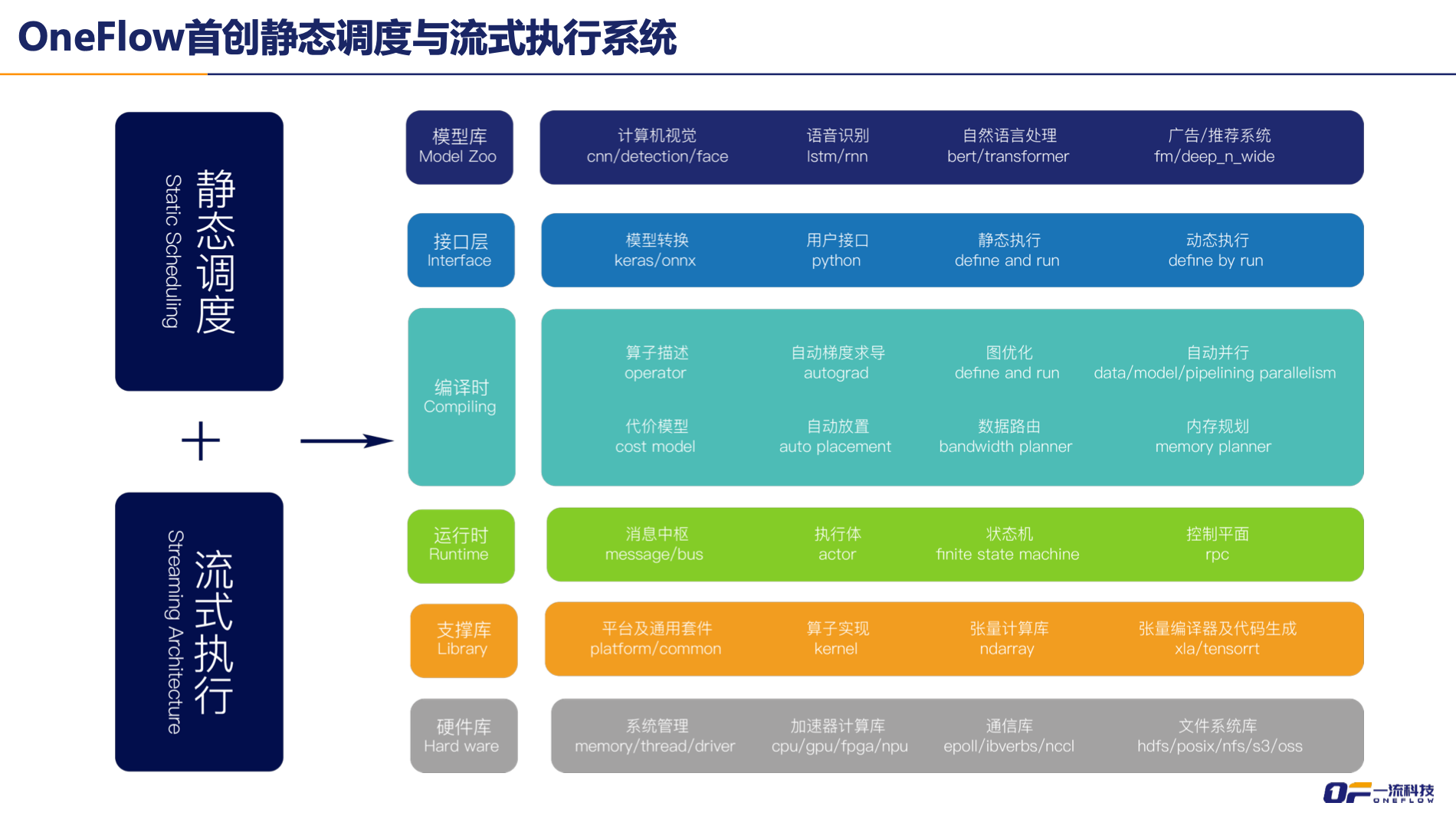
去中心化协议:在运行任务时,不再需要中心调度器,只需要支持上下游任务之间局部的握手信号即可,即生产者向消费者发送的请求以及消费者向生产者发送的确认,整个系统以全链路异步的方式运行。
流式执行引擎:区别于其它深度学习框架把数据搬运当成二等公民,OneFlow将数据搬运看作一等公民。在静态分析阶段,OneFlow就把磁盘 IO、主存和设备之间数据搬运,节点间数据搬运看作和计算同等重要的任务,在代价分析和调度策略里作为一等公民进行显式建模,从而得到重叠传输和计算的最优方案。
深度学习框架的演进路线
作为新生代深度学习框架,尽管OneFlow在易用性和高效性上具有不俗实力,但它要想在未来进一步扩大在开发者社区中的竞争力,还需要在算子、模型库等完备性上补足功课,而这需要更多社区开发者参与其中。
未来,OneFlow深度学习框架将如何发展?一流科技创始人&袁进辉给出了他的判断:
框架平台标准化:深度学习算法的标准化,带来了软件标准化的机会,深度学习框架正在走向标准化。
生态决定框架未来的竞争力:之江实验室、北京智源人工智能研究院、粤港澳大湾区数字经济研究院、之江实验室、中关村智用人工智能研究院等顶尖AI科研院所已使用OneFlow框架开展研究工作。同时,联合寒武纪、燧原科技、曙光DCU等芯片、云厂商上下游企业,推进适配OneFlow框架的超大模型训练方案。下一步,一流科技将推动与更多芯片厂商和广大开发者的合作,打造AI平台的繁荣生态。
软件2.0趋势:前特斯拉AI 负责人Andrej Karpathy曾指出,软件 1.0 的“经典堆栈”是用 Python、C++ 等语言编写的计算机显式指令,与 软件1.0 不同,软件 2.0 用深度学习模型从数据中自动推导生成软件的编程范式,深度学习框架极有可能会朝这一方向迈进。
像数据库产品那样提供标准化服务
面向社区开发者,一流科技在不断提升OneFlow框架用户体验;与此同时,作为一个商业化公司,基于OneFlow框架,相应推出了标准化解决方案,包括云边端AI基础设施OneBrain、OneAgent智能决策平台和OneFlow智能云平台。他们认为,AI产业化机会在于标准化的基础设施和云原生趋势。

OneBrain开发平台具有丰富的开发模式,支持高性能分布式训练、多租户的资源调度和混合云的解决方案。
通过私有化部署,用户可以在OneBrain上可以实现多租户和多任务管理,支持可视化、日志分析等功能,根据用户的集成规模、节点、使用时长等计费。
OneAgent智能决策平台是一个基于深度强化学习的平台,它创造性地使用了微服务架构,主要面向无人对战、路径规划、态势感知与智能博弈、金融量化交易等深度强化学习的应用场景。
此外,OneFlow智能云平台作为面向广大开发者的AI实训与开发平台,提供精品算法讲解、开源算法实测、在线编程环境及算力。它能帮助开发者快速掌握深度学习开发的相关技能,边学边连。未来,OneFlow智能云平台还将面向中小企业用户提供PaaS和SaaS服务,帮助更多企业用AI赋能生产和管理。
目前,一流科技已服务十多家客户,尤其是对性能、大规模分布式场景有迫切需求的头部互联网公司、安防公司、政务云、科研院所等机构,涵盖图像、自然语言处理、金融、广告/推荐等应用场景。














